Sebastian Edwards has written an interesting new book about FDR’s devaluation of the dollar and the legal and economic consequences thereof. This post is not about the book, although I do recommend it. What I would like to write about is motivated by some of the reaction to this book that I’ve seen and heard regarding gold and the gold standard. In recent years, I have become convinced that what I thought was the conventional wisdom on the gold standard is not widely understood. So I’d like to write a series of posts on the gold standard and how it worked. My tentative plan is as follows:
Part 1. The efficiency of the gold standard.
Part 2. The determination of the price level under the gold standard.
Part 3. The Monetary Approach to the Balance of Payments vs. the Price-Specie Flow Mechanism
Part 4. Gold standard interpretations of the Great Depression.
I don’t have a timeline for when these will be posted, but it is my hope to have them posted in a timely fashion so that they can get the appropriate readership. With that being said, let’s get started with Part 1: The efficiency of the gold standard.
Some people define the gold standard in their own particular way. I want to use as broad of a definition as possible. So I will define the gold standard as any monetary system in which the unit of account (e.g. the dollar) is defined as a particular quantity of gold. This definition is broad enough to encapsulate a wide variety of monetary systems, including but not limited to free banking and the pre-war international gold standard. Given this definition, the crucial point is that when the unit of account is defined as a particular quantity of gold, this implies that gold has a particular price in terms of this unit of account. In other words, if the unit of account is the dollar, then all prices are quoted in terms of dollars. The price of gold is no different. However, since the dollar is defined as a particular quantity of gold, this implies that the price of gold is fixed. For example, if the dollar is defined as 1/20 of an ounce of gold, then the price of an ounce of gold is $20.
This type of characteristic poses a lot of questions. Does the market accept this price? Or, is there any tendency for the market price of gold to equal the official, or mint price? This is a question of efficiency. If the market price of gold differs substantially from the official price, then the gold standard cannot be thought of as efficient and one must consider the implications thereof for the monetary system. What determines the price level under this sort of system? Does the quantity theory of money hold? What about purchasing power parity? In many ways, these questions are central to understanding not only of how the gold standard worked, but also the nature of business cycles under a gold standard. The price level and purchasing power parity arguments are equilibrium-based arguments. This raises the question as to what mechanisms push us in the direction of equilibrium. We therefore need to compare and contrast the monetary approach to the balance of payments with the price-specie flow mechanism. Finally, given this understanding, I will use the answers of this question to gain some insight into the role of the gold standard with regards to the Great Depression.
In terms of efficiency, we can think about the efficiency of the gold market in one of two ways. We could consider the case in which the dollar is the only currency defined in terms of gold. In this case, the U.S. would have an official price of gold, but gold would be sold in international markets and the price of gold in terms of foreign currencies is entirely market-determined. Alternatively, we could consider the case of an international gold standard in which many foreign currencies are defined as a particular quantity of gold. For simplicity, I will use the latter assumption.
This first post is concerned with whether or not the gold standard was efficient. So let’s consider the conditions under which the gold standard could be considered efficient. We would say that the gold standard is efficient if there is (a) a tendency for the price of gold to return to its official price, and (b) if market price of gold doesn’t different too much from the official price.
Under the assumption that multiple countries define their currency in terms of the quantity of gold, let’s consider a two country example. Suppose that the U.S. defines the dollar as 1/20 of an ounce of gold and the U.K. defines the pound as 1/4 of an ounce of gold. It follows that the price of one ounce of gold is $20 in the U.S. and £4. Note that this implies that $20 should buy £4. Thus, the exchange rate should be $5 per pound. We can use this to discuss important results.
Suppose that the current exchange rate is equal to the official exchange rate. Suppose that I borrow 1 pound at an interest rate  for one period and then exchange those pounds for dollars and invest those dollars in some financial instrument in the U.S. that pays me a guaranteed rate of
for one period and then exchange those pounds for dollars and invest those dollars in some financial instrument in the U.S. that pays me a guaranteed rate of  for one period.
for one period.
The cost of my borrowing when we reach the next period is  . But remember, I exchanged pounds for dollars in the first period and 1 pound purchased 5 dollars and invested these dollars. So my payoff is
. But remember, I exchanged pounds for dollars in the first period and 1 pound purchased 5 dollars and invested these dollars. So my payoff is  . I will earn a profit if I sell the dollars I received from this payoff for pounds, pay off my loan, and have money left over. In other words, consider this from the point of view in period 1. In period 1, I’m borrowing and using my borrowed funds to buy dollars and invest those dollars. In period 2, I receive a payoff in terms of dollars that I sell for pounds to pay off my loan. If there are any pounds left over, then I have made an arbitrage profit. Let
. I will earn a profit if I sell the dollars I received from this payoff for pounds, pay off my loan, and have money left over. In other words, consider this from the point of view in period 1. In period 1, I’m borrowing and using my borrowed funds to buy dollars and invest those dollars. In period 2, I receive a payoff in terms of dollars that I sell for pounds to pay off my loan. If there are any pounds left over, then I have made an arbitrage profit. Let  denote the forward exchange rate (the exchange rate in period 2), defined as pounds per dollar. It follows that I can write my potential profit in period 2 as
denote the forward exchange rate (the exchange rate in period 2), defined as pounds per dollar. It follows that I can write my potential profit in period 2 as

We typically assume that in equilibrium, there is no such thing as a perpetual money pump (i.e. we cannot earn a positive rate of return with certainty with an initial investment of zero). This implies that in equilibrium, this scheme is not profitable. Or,
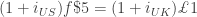
Re-arranging we get:
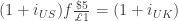
This is the standard interest parity condition. Note that is defined as pounds per dollar. If the gold standard is efficient we would expect the forward exchange rate to equal to official exchange rate (we should rationally expect that the gold market tends toward equilibrium and the official prices hold). Thus, one should expect that  . Plugging this into our no-arbitrage condition implies that:
. Plugging this into our no-arbitrage condition implies that:

In other words, the interest rate in both countries should be the same. There is a world interest rate that is determined in international markets.
However, remember that this is an equilibrium condition. Thus, at an point in time there is no guarantee that this condition holds. In fact, in our arbitrage condition, we assumed that there are no transaction costs associated with this sort of opportunity. In addition, under the gold standard, we do not have to exchange dollars for pounds or pounds for dollars. We can exchange dollar or pounds for gold and vice versa. Thus, under the gold standard what we really care about are market prices of the same asset in terms of dollars and pounds. For example, consider a bill of exchange. The price paid for a bill of exchange is the discounted value of the face value of the bill.
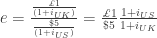
So if the ratio of the prices of these bills differ from the official exchange rate, there is a potential for arbitrage profits. As the equation above implies, this can be reflected in the ratio of interest rates. However, it can also simply be observed from the actual prices of the bills.
Officer (1986, p. 1068 – 1069) describes how this was done in practice (referencing import and export points as what we might call an absorbing barrier under which it made sense to engage in arbitrage, given the costs):
In historical fact, however, cable drafts in the pre-World War I period were dominated by demand (also called “sight”) bills as the exchange medium for gold arbitrage. Purchased at a dollar market price in New York, the bill would be redeemed at it pound face value on presentation to the British drawee, with the dollar-sterling exchange rate give by the market price/face value ratio. When this rate was greater than the (demand bill) gold export point, American arbitrageurs (or American agents of British arbitrageurs) would sell demand bills, use the dollars thereby obtained to purchase gold from the U.S. Treasury, ship the gold to London, sell it to the Bank of England, and use part of the proceeds to cover the bills on presentation, with the excess amount constituting profit.
[…]
When the demand bill exchange rate fell below the gold import point, the American arbitrageur would buy demand bills, ship them to Britain, present them to the drawees, use the proceeds to purchase gold from the Bank of England, ship the gold to the United States, and (if not purchased in the form of U.S. coin) convert it to dollars at the U.S. mint.
Thus, we can think of interest rate differentials as opportunities for arbitrage directly, or as reflecting the current market exchange rate. In either case, the potential opportunities for arbitrage profits ultimately kept gold near parity. In fact, Officer (1985, 1986) shows that gold market functioned efficiently (and in accordance with our definition of efficiency).
With this in mind, we have a couple of important questions. This discussion focuses entirely on the microeconomics of the gold standard. In subsequent posts, I will shift the discussion to macroeconomic topics.





