Greece is currently seeking a bailout from the European Union. However, negotiations (at least as I write this) are at a standstill. Greece wants a bailout, but the new Greek government has indicated that it is unwilling to enact so-called austerity reforms. During the negotiations, the European Central Bank has given emergency funding to the Greek financial system. However, this funding is conditional on the negotiations between Greece and the EU. The finance ministers of various EU countries want Greece to commit to reducing their debt in line with their 2012 commitments. Since Greece appears unwilling to meet those requirements, the support from the ECB is likely to stop by the end of the month. Thus, Greece could face a significant financial crisis if no deal is reached.
In the midst of these negotiations, some have argued that the EU, and Germany specifically, do not appear to understand the magnitude of the situation. Paul Krugman, for instance, writes
As long as it stays on the euro, then, Greece needs the good will of the central bank, which may, in turn, depend on the attitude of Germany and other creditor nations.
But think about how that plays into debt negotiations. Is Germany really prepared, in effect, to say to a fellow European democracy “Pay up or we’ll destroy your banking system?”
[…]
Doing the right thing would, however, require that other Europeans, Germans in particular, abandon self-serving myths and stop substituting moralizing for analysis.
This last statement is particular telling. Many commentators agree with Krugman and view the Germans and other members of the EU as moralizing. In other words, they are not using economic analysis, but rather relying on their own views about right and wrong and how a government should operate. However, I would submit that rather than assuming that the Germans and other members of the EU are vindictive moralizers, an understanding of economics can actually teach us why EU members have taken their current position. But to understand why, we need to know something about rent-seeking.
Suppose that there are two countries, Germany and Greece. In addition, suppose that each of these countries have an endowment of resources, 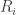 , where
, where 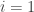 will refer to Germany and
will refer to Germany and 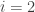 will refer to Greece. Now let’s assume that each country can devote some amount of resources to production,
will refer to Greece. Now let’s assume that each country can devote some amount of resources to production,  and some amount of time to fighting with each other,
and some amount of time to fighting with each other,  . It follows that each country has a resource constraint:
. It follows that each country has a resource constraint:
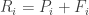
Now, let’s assume that the total production between the two countries is given as

where  is a measure of complementarity in production. One way to think about
is a measure of complementarity in production. One way to think about  is that the higher its value, the most closely linked the two countries are in terms of international trade, production, etc.
is that the higher its value, the most closely linked the two countries are in terms of international trade, production, etc.
Thus, we see that the countries can commit their resources to production or to fighting. The more each country contributes to production, the higher the total level of production. However, fighting with one another can also provide benefits (this obviously doesn’t have to refer to actual fighting, it could refer to negotiations like those that are ongoing). However, whereas increased production will cause an increase in the amount of production/income that is generated, fighting will only have an effect on the distribution of income.
Thus, each country faces a trade-off. The more resources they commit to production, the higher the level of income that is generated. The more resources they commit to fighting, the greater the distribution of the existing income they receive (but there is less income as a result). Thus each country has to choose the share of resources that they want to commit to production and fighting.
We will assume that there is a contest success function (as in Tullock, 1980) that is a function of the amount of resources that each country commits to fighting. For Germany, we assume that the contest success function is given as

where  is an index of the decisiveness of the conflict. Correspondingly, for Greece
is an index of the decisiveness of the conflict. Correspondingly, for Greece  .
.
Given these definitions, we can then define the distribution of income:


Now let’s assume that each country wants to maximize their own income 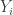 , taking what the other country is doing as given. Thus, each country wants to maximize the following
, taking what the other country is doing as given. Thus, each country wants to maximize the following
![\max\limits_{P_i, F_i} {{F_i^m}\over{F_i^m + F_j^m}} [(P_1^{1/s} + P_2^{1/s})^s]](https://s0.wp.com/latex.php?latex=%5Cmax%5Climits_%7BP_i%2C+F_i%7D+%7B%7BF_i%5Em%7D%5Cover%7BF_i%5Em+%2B+F_j%5Em%7D%7D+%5B%28P_1%5E%7B1%2Fs%7D+%2B+P_2%5E%7B1%2Fs%7D%29%5Es%5D&bg=ffffff&fg=333333&s=0&c=20201002)

In equilibrium, it follows that

Now let’s use this equilibrium condition to understand the interaction between Germany and Greece. Suppose that we simply choose resource endowments of $R_1 = 100$ and $R_2 = 50$ thereby assuming that Germany has twice as many resources as Greece. Now let’s consider the implications under two scenarios. First, we will consider the scenario in which  . In this case, total production is just the sum of German and Greek production. It follows from equilibrium that
. In this case, total production is just the sum of German and Greek production. It follows from equilibrium that

Thus, in this case, Germany and Greece devote the same amount of resources to the fighting. However, since Germany has twice as many resources as Greece, it follows that Greece is devoting a larger percentage of their resources to fighting. In devoting resources to fighting, the two countries produce less total production. To see this, consider that if each country devoted all of their resources to production, total production would be 100 + 50 = 150. If we assume that 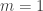 , then
, then  . Thus, total production is 62.5 + 12.5 = 75. And yet this is their optimal choice given what they expect the other country to do!
. Thus, total production is 62.5 + 12.5 = 75. And yet this is their optimal choice given what they expect the other country to do!
As a result of the percentage of resources devoted to fighting, Greece gets 1/2 of the resulting production, despite only having 1/3 of the total resources. It should therefore be straightforward to understand why Greece is devoting so many resources to getting a larger bailout without bearing the costs of so-called austerity measures. In addition, it is important to note that it is in Germany’s best interest to devote resources to fighting, given what they expect Greece to do.
It is straightforward to show two other results with this framework. First, as increases, the weaker side has less of an incentive to fight whereas the stronger side has a greater incentive to fight. In other words, when production becomes more complementary, then the poorer side has less of an incentive to fight because of the linkages in production between their production effort and the other country. While the richer country has an incentive to fight more, the total resources devoted to fighting will fall.
Again, this informs the discussion about Germany and Greece in comparison to other countries. If you want to understand why there seems to be a greater conflict between Germany and Greece than between Germany and other EU countries, consider that Greece is Germany’s 40th largest trading partner, just after Malaysia and just ahead of Slovenia. All else equal the model described above suggests that we should expect more resources devoted to conflict.
The second characteristic has to do with the decisiveness of conflict. As increases, the conflict between the two countries can be considered more decisive. As the conflict becomes more decisive, the model predicts that the sides will have more of an incentive to devote to fighting. Thus, if Germany believes that this is (or should be) the last round of negotiations with Greece, then we would expect them to devote more resources to fighting.
So what is the point of this exercise?
The entire point of this exercise is to understand that Germany is, in fact, acting in their own economic interest given what they expect Greece to do. If we want to understand the positions of Germany and Greece, we need to understand strategic behavior. Germany’s refusal to simply give in to Greece’s demands and “do what’s best for Europe” ignores a lot of the aspects of what is going on here. Those who think that Germany is being too harsh ignore some of the key aspects of the framework discussed above.
First, one should note that the distribution of income in the framework above is always more equal to the distribution of resources. Thus, it pays for Greece to fight. However, Germany knows that it pays for Greece to fight and therefore Germany’s best strategic decision is to devote resources to fighting as well.
Second, by claiming that Germany is failing to do what is in the “best interests of Europe”, the critics are presuming that they know the social welfare function that needs to be maximized. Perhaps they are correct. Perhaps they are not. But even if these critics are correct, this doesn’t mean that Germany’s behavior is incomprehensible or that it is based on something other than economics. Rather the confusion is on the part of the critics who fail to understand that a Nash equilibrium may or may not be the socially desirable equilibrium. Germany’s rhetoric might be moralizing, but we can understand their behavior through an understanding of economics. And this is true whether you like Germany’s behavior or not.
[This post is an application of Hirshleifer’s Paradox of Power model. See here.]

![E_0 \sum_{t = 0}^{\infty} \beta^t [u(q_t) - x_t]](https://s0.wp.com/latex.php?latex=E_0+%5Csum_%7Bt+%3D+0%7D%5E%7B%5Cinfty%7D+%5Cbeta%5Et+%5Bu%28q_t%29+-+x_t%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 is the discount factor,
is the discount factor,  is the quantity of goods purchased in the DM, and
is the quantity of goods purchased in the DM, and  is the quantity of goods produced by the buyer in the CM. Consumption of the DM good provides utility to the buyer and production of the CM good generates disutility of production. Here, the utility function satisfies
is the quantity of goods produced by the buyer in the CM. Consumption of the DM good provides utility to the buyer and production of the CM good generates disutility of production. Here, the utility function satisfies  .
.
 denotes the price of money in terms of goods,
denotes the price of money in terms of goods, 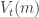 and the value function for buyers entering the CM as
and the value function for buyers entering the CM as  .
.![W_t(m) = \max_{x,m'} [-x_t + \beta V_{t + 1}(m')]](https://s0.wp.com/latex.php?latex=W_t%28m%29+%3D+%5Cmax_%7Bx%2Cm%27%7D+%5B-x_t+%2B+%5Cbeta+V_%7Bt+%2B+1%7D%28m%27%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![W_t(m) = \phi_t m + \max_{m'} [-\phi_t m' + \beta V_{t + 1}(m')]](https://s0.wp.com/latex.php?latex=W_t%28m%29+%3D+%5Cphi_t+m+%2B+%5Cmax_%7Bm%27%7D+%5B-%5Cphi_t+m%27+%2B+%5Cbeta+V_%7Bt+%2B+1%7D%28m%27%29%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 where
where ![d \in [0,m]](https://s0.wp.com/latex.php?latex=d+%5Cin+%5B0%2Cm%5D&bg=ffffff&fg=333333&s=0&c=20201002) represents the quantity of money balances offered for trade and
represents the quantity of money balances offered for trade and 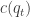 represents the disutility generated by sellers from producing the DM good. The value function for buyers in the DM is given as
represents the disutility generated by sellers from producing the DM good. The value function for buyers in the DM is given as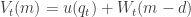
 and the conditions of the buyers' offer, this can be re-written as:
and the conditions of the buyers' offer, this can be re-written as:
![max_{m} \bigg[-\bigg({{\phi_t/\phi_{t + 1}}\over{\beta}} - 1\bigg)\phi_{t + 1} m + u(q_{t+1}) - c(q_{t+1}) \bigg]](https://s0.wp.com/latex.php?latex=max_%7Bm%7D+%5Cbigg%5B-%5Cbigg%28%7B%7B%5Cphi_t%2F%5Cphi_%7Bt+%2B+1%7D%7D%5Cover%7B%5Cbeta%7D%7D+-+1%5Cbigg%29%5Cphi_%7Bt+%2B+1%7D+m+%2B+u%28q_%7Bt%2B1%7D%29+-+c%28q_%7Bt%2B1%7D%29+%5Cbigg%5D&bg=ffffff&fg=333333&s=0&c=20201002)
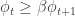 . Intuitively, this means that the value of holding fiat money today is greater than or equal to the discounted value of holding money tomorrow. If this condition is violated, everyone would be better off holding their money until tomorrow indefinitely. No monetary equilibrium could exist.
. Intuitively, this means that the value of holding fiat money today is greater than or equal to the discounted value of holding money tomorrow. If this condition is violated, everyone would be better off holding their money until tomorrow indefinitely. No monetary equilibrium could exist. ). This means that the buyers' offer can now be written
). This means that the buyers' offer can now be written  . This gives us the necessary envelope conditions to solve the maximization problem above. Doing so, yields our equilibrium difference equation that will allow us to talk about the effects of the platinum coin. The difference equation is given as
. This gives us the necessary envelope conditions to solve the maximization problem above. Doing so, yields our equilibrium difference equation that will allow us to talk about the effects of the platinum coin. The difference equation is given as![\phi_t = \beta \phi_{t + 1}\bigg[ \bigg(u'(q_{t + 1})/c'(q_{t + 1}) - 1 \bigg) + 1 \bigg]](https://s0.wp.com/latex.php?latex=%5Cphi_t+%3D+%5Cbeta+%5Cphi_%7Bt+%2B+1%7D%5Cbigg%5B+%5Cbigg%28u%27%28q_%7Bt+%2B+1%7D%29%2Fc%27%28q_%7Bt+%2B+1%7D%29+-+1+%5Cbigg%29+%2B+1+%5Cbigg%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 . Thus, the difference equation can be written:
. Thus, the difference equation can be written:![\phi_t = \beta \phi_{t + 1}\bigg[ \bigg(u'(q)/c'(q) - 1 \bigg) + 1 \bigg]](https://s0.wp.com/latex.php?latex=%5Cphi_t+%3D+%5Cbeta+%5Cphi_%7Bt+%2B+1%7D%5Cbigg%5B+%5Cbigg%28u%27%28q%29%2Fc%27%28q%29+-+1+%5Cbigg%29+%2B+1+%5Cbigg%5D&bg=ffffff&fg=333333&s=0&c=20201002)
 and
and  have standard functional forms. Specifically, assume that
have standard functional forms. Specifically, assume that  and
and  . [I should note that the conclusions here are robust to more general functional forms as well.] If this is the case, then the difference equation is a convex function up to a certain point at which the difference equation becomes linear. The convex portion is what is important for our purposes. The fact that the difference equation is convex implies that the difference equation intersects the 45-degree line used to plot the steady-state equilibrium in two different places. This means that there are multiple equilibria. One equilibrium, which we will call
. [I should note that the conclusions here are robust to more general functional forms as well.] If this is the case, then the difference equation is a convex function up to a certain point at which the difference equation becomes linear. The convex portion is what is important for our purposes. The fact that the difference equation is convex implies that the difference equation intersects the 45-degree line used to plot the steady-state equilibrium in two different places. This means that there are multiple equilibria. One equilibrium, which we will call  is the equilibrium that is assumed to be the case by advocates of the platinum coin. They assume that if we begin in this equilibrium, the Federal Reserve can simply hold the money supply constant through open market operations and in so doing prevent the price of money (i.e. the inverse of the price level) from fluctuating.
is the equilibrium that is assumed to be the case by advocates of the platinum coin. They assume that if we begin in this equilibrium, the Federal Reserve can simply hold the money supply constant through open market operations and in so doing prevent the price of money (i.e. the inverse of the price level) from fluctuating.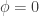 ). Put in economic terms, there are multiple equilibria that are decreasing in
). Put in economic terms, there are multiple equilibria that are decreasing in 
